Dan Taylor
Still crushin’ it
-
 Vibe Coding like it's 2025
Vibe Coding like it's 2025
-
 Leadership Tips of the Week
Leadership Tips of the Week
-
 Data, Science and Biscuits
Data, Science and Biscuits
-
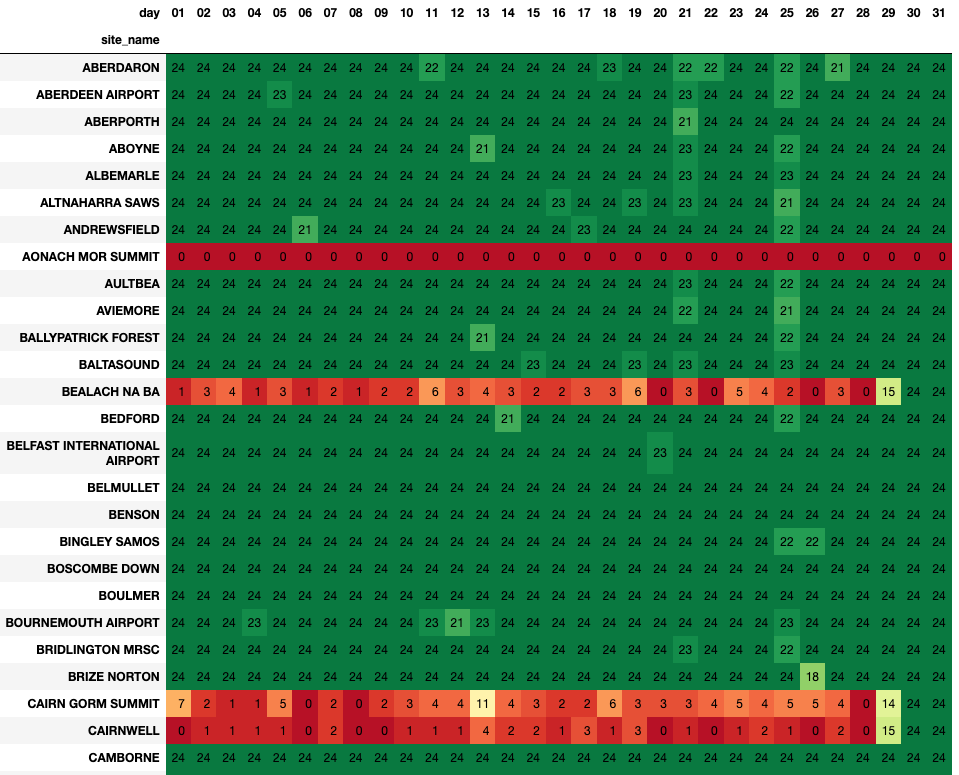 World's Simplest Data Model?
World's Simplest Data Model?
-
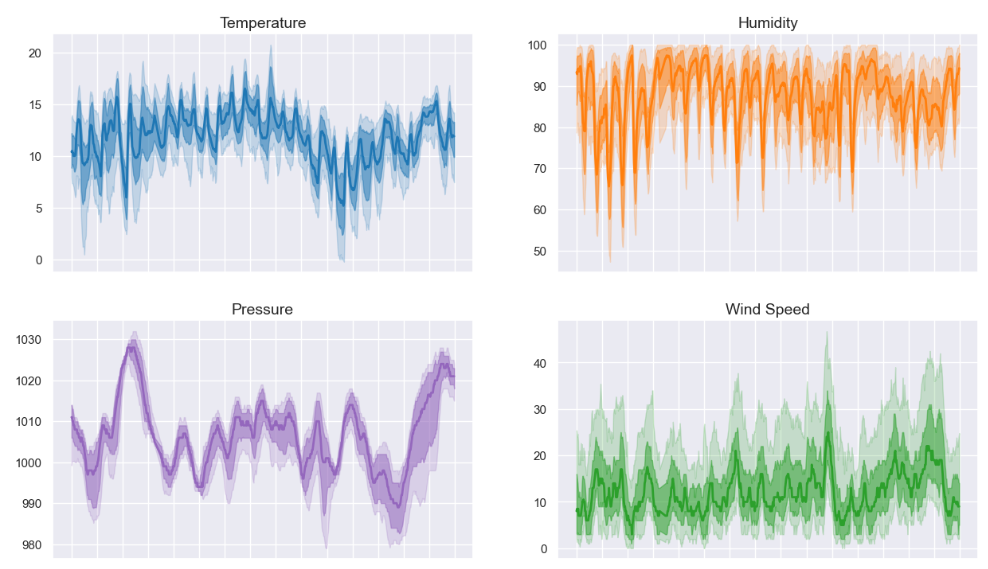 World's Simplest Data Pipeline?
World's Simplest Data Pipeline?
-
 The Data Compass: How to Build a Data Strategy
The Data Compass: How to Build a Data Strategy
-
 Stuff I made in 2020
Stuff I made in 2020
-
 Stuff I made in 2019
Stuff I made in 2019
-
 How to Break the Curse of Legacy Data
How to Break the Curse of Legacy Data
-
Data Science Festival
-
 Stuff I made in 2018
Stuff I made in 2018
-
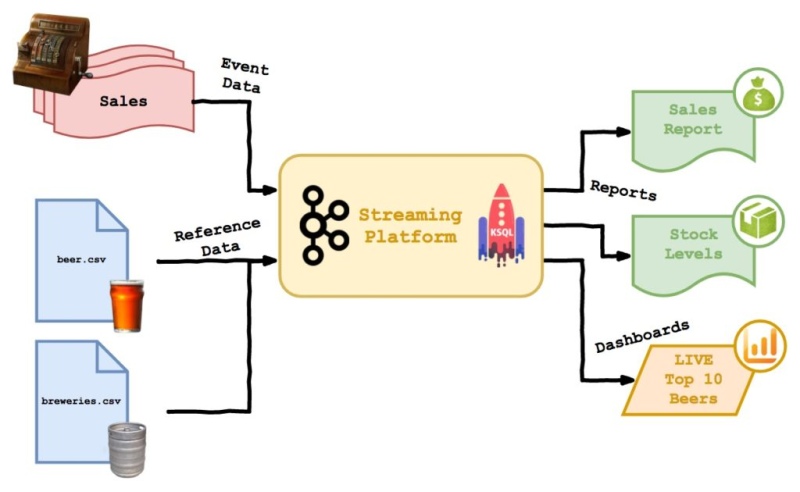 One for the Road
One for the Road
-
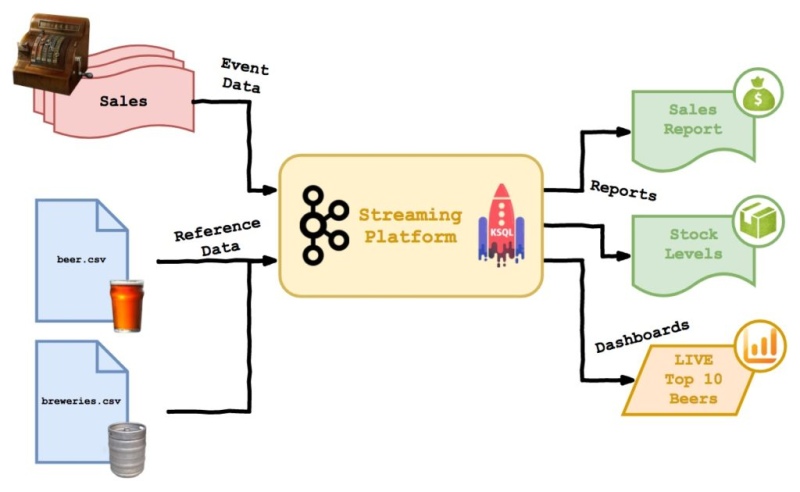 Time at the Bar Chart
Time at the Bar Chart
-
 Kafka's Beer Festival
Kafka's Beer Festival
-
 Data Engineering in Real Time
Data Engineering in Real Time
-
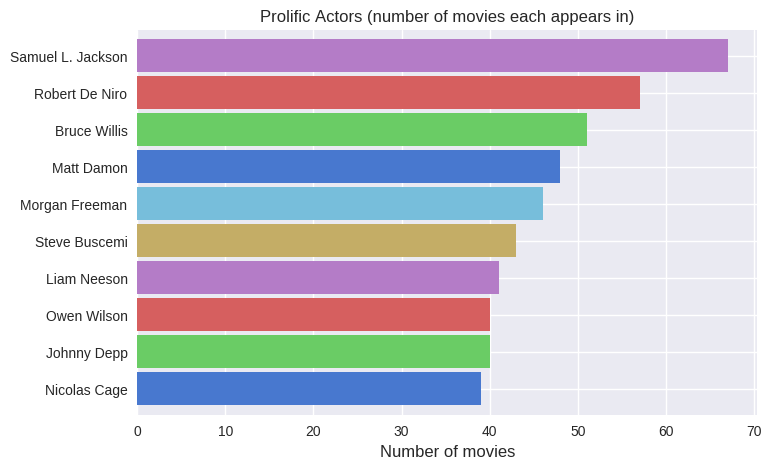 A Trip to the Movies
A Trip to the Movies
-
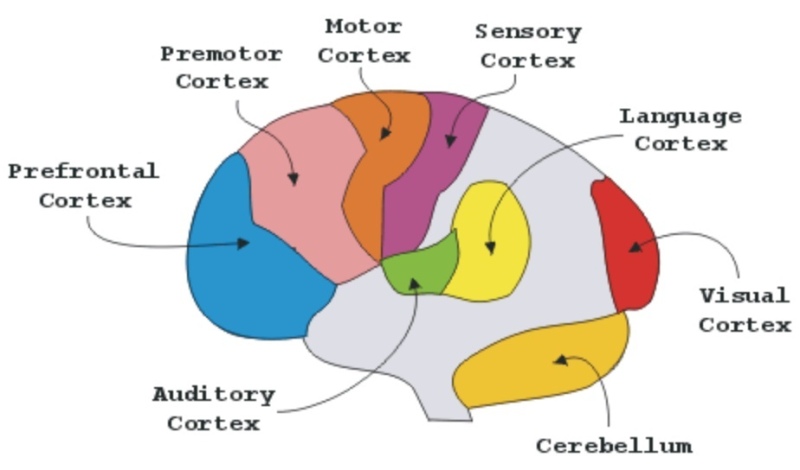 Face Clustering II: Neural Networks and K-Means
Face Clustering II: Neural Networks and K-Means
-
 Face Clustering with Python
Face Clustering with Python
-
 Stuff I made in 2017
Stuff I made in 2017
-
Controlling a TP-Link Smart Bulb with Python and Requests
-
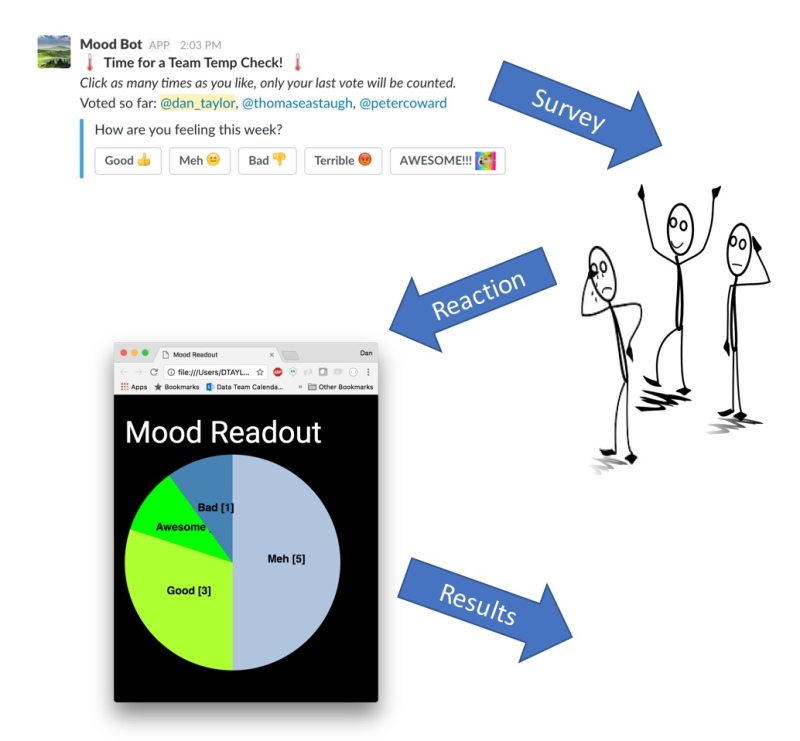 Mood Bot - a Serverless Slack Integration
Mood Bot - a Serverless Slack Integration
-
 Amazon Athena - First Look
Amazon Athena - First Look
-
 Evolutionary Algorithm: Playable Demo
Evolutionary Algorithm: Playable Demo
-
 Conway's Game of Life
Conway's Game of Life