Data Engineering in Real Time
November 21, 2018
This article is part 1 of a mini-series about events and models. The following parts are quite technical, with Kafka, Scala and KSQL code, but this part is a bit of an introduction to the problem at hand. Enjoy!
I’m a Data Engineer by trade. I’ve been working with Data Platforms for some years now, usually building tools to ingest and manage data, in a whole heap of industries from supermarket fridges to telecoms networks to insurance websites. Each industry has it’s own unique challenges, be it latency, data volume or data quality but each use-case has ended up being essentially the same…
"The fundamental role of a Data Engineer is to translate events into entities"- Dan Taylor, Today
Our lives, the universe, everything is simply a stream of events. People buy things on websites, make calls on their phones, order beers, click like on cat videos. Everything that makes us who we are can be encapsulated in a time-ordered change log. These days, many companies are adopting event-driven architectures to handle the endless firehose of stuff that happens.
Humans, however, don’t think in terms of events - they think in terms of of things*: *How much money do I have? How many customers bought avocados? What’s the mobile coverage like in my street? We just can’t help but think in terms of entities and attributes. As a result, pretty much every company still has an old-school BI function; a SQL data warehouse; an enterprise data model (or just an ER diagram on the office wall); overnight batch ETL jobs; daily and monthly reports… These old-school tools help us to rationalise the world in a way that feels natural.
The job of Data Engineers is to collect, filter, clean and store the endless stream of events and to map the changes they represent onto an entity-based model of the ‘world’.
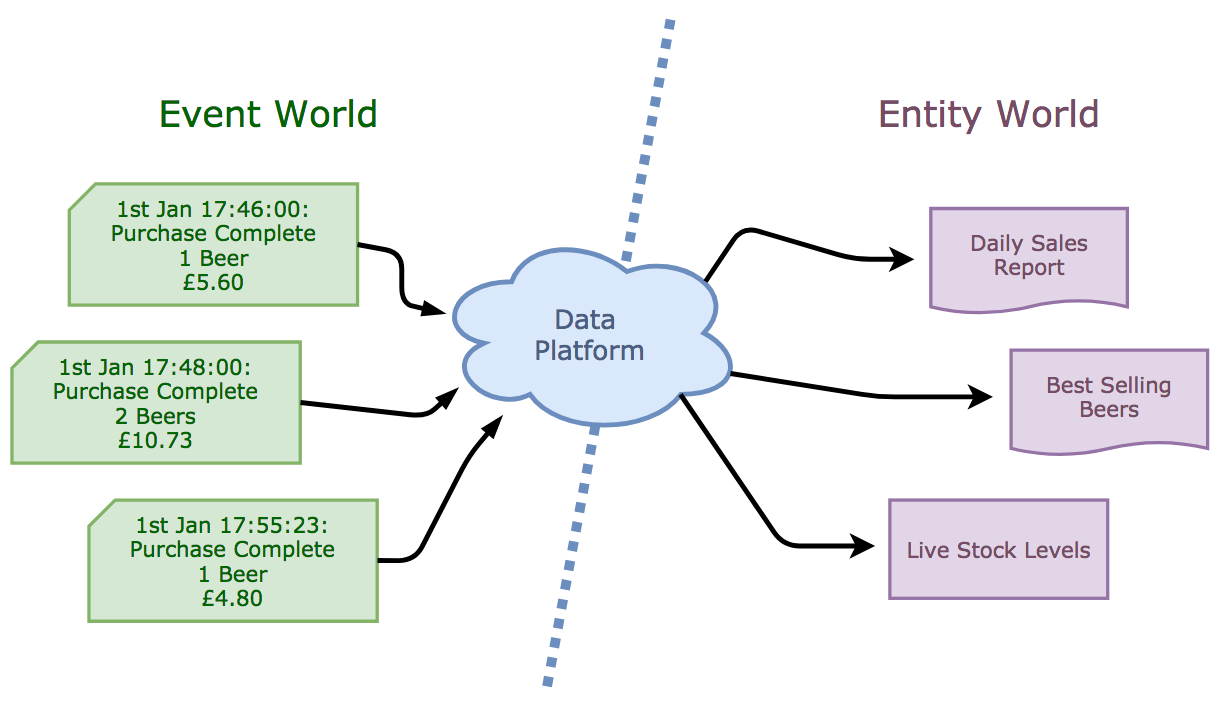
What surprises me is that, even though this problem has been around forever (as far back as the 50’s and 60’s in fact) there is no standard pattern for solving it. As the latency of life decreases and we start to eek out the margin from every single minute and second, the pressure mounts to paint an accurate picture of our customers and systems in real time, 24x7.
Batch Processing
In the olden days… by which I mean, this still happens now, but when asked about it, people look sheepish and refer to it as “legacy”… anyway, in the olden days conversion from events to models happened as an overnight batch. Take this classic example of a bank…
Every night, all reporting operations stop, while a monstrous ETL job aggregates all the transactions from the past 24 hours, adds them to the yesterday’s account balances and updates the master database. Remember when your bank balance changed once a day?
There’s actually nothing wrong with this! Locking users out for a couple of hours while running an overnight job is a great way to ensure that everyone arrives in the office next day to a view of the world which is correct, consistent, stable and reliable. It’s perfect for financial reporting, where accuracy is more important than timeliness… but if you want a more up-to-date view, you have to come back tomorrow.
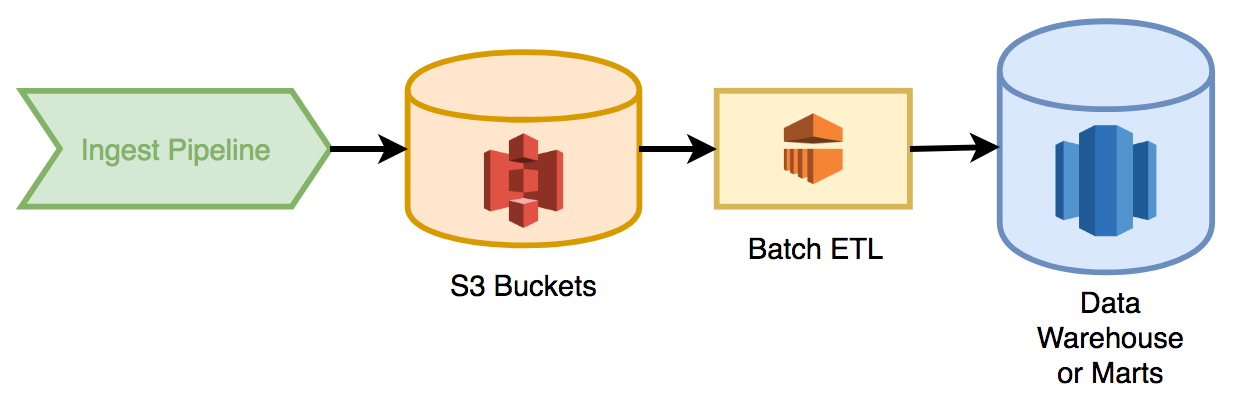
A modern batch process would usually be used to populate bulk data in warehouses and data marts used for financial reporting and long term forecasting. Updating overnight means results are consistent all day, across all reports/departments etc. In a typical AWS deployment, data is tapped from the ingest pipeline and archived to a “data lake” as files in S3. Overnight a series of EMR pipelines pick up, aggregate and transform the raw data, storing the results into a relational database like RedShift.
Streaming and Event Sourcing
In the front office, things have been changing over the last few years. For all sorts of sensible reasons, the front-end folks are moving away from fat, monolithic applications, desktop clients and complex MVC apps towards lightweight micro-services. The single responsibility principal now applies to services not classes, and scores of them are wired together in complex webs promoting re-use, scalability and a clear separation of concerns.
But getting consistent and repeatable results from a complex web of services is hard. Timing starts to play a big part in what happens, as calls happen slightly earlier or later and the state of data in services becomes prone to race conditions and emergent behaviour. For this reason, the next step on from micro services is Event Sourcing, which uses a central log of events to give consistency, repeatability and traceability.
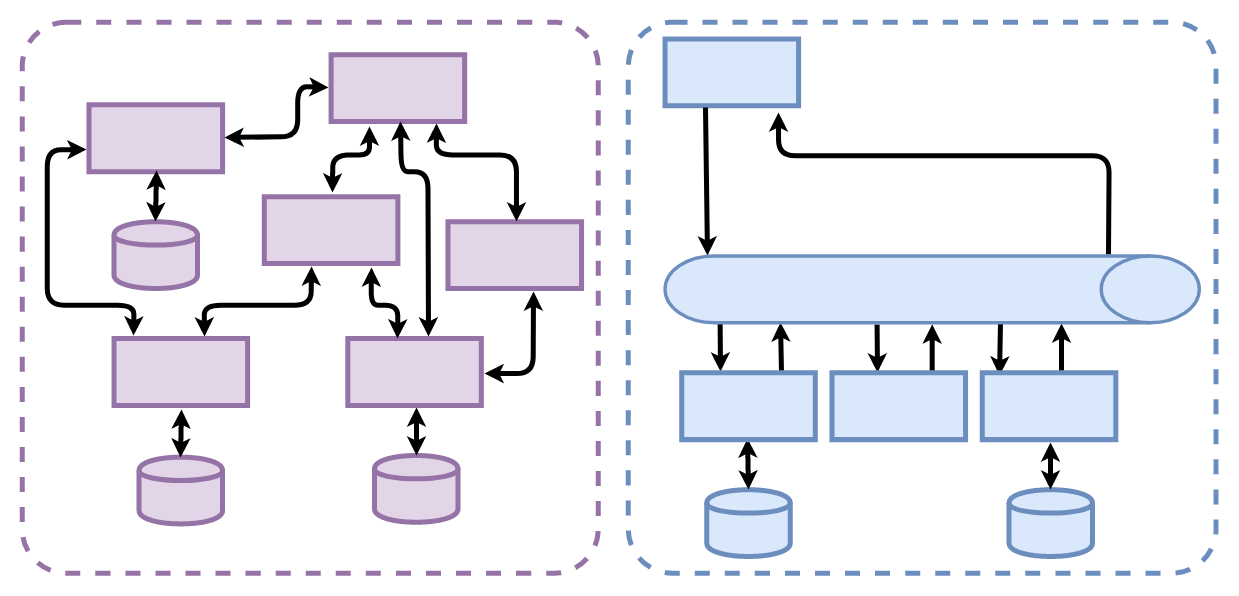
To cut a long story short, the front office is now sending events to record everything that happens, as it happens, in real time. If Data teams are going to join in the fun, then all our reports, models and snazzy-pants neural networks need to play the same game. We need to be predicting a customer’s next action now, not overnight. Which means we now need to convert events into models in real time.
Events to Models in Real Time
The challenge is simple - we need to process a stream of events, ensuring that every change is immediately mapped onto a database entity. The standard, simple, usual way to do this is to just use a fast database as a cache, thus:
foreach(event : ProductPurchasedEvent) {
with(new DatabaseTransaction) {
customer = cacheDB.selectOrCreateCustomerRecord(event.customerId)
customer.productsPurchased++
customer.mostRecentProduct = event.productId
cacheDB.saveCustomerRecord(customer)
}
}
Every time a customer buys a product, we pull their customer record from the cache database, update the appropriate fields and write the data back. Since we want to avoid race conditions and respect running queries, this is all done under a transaction.
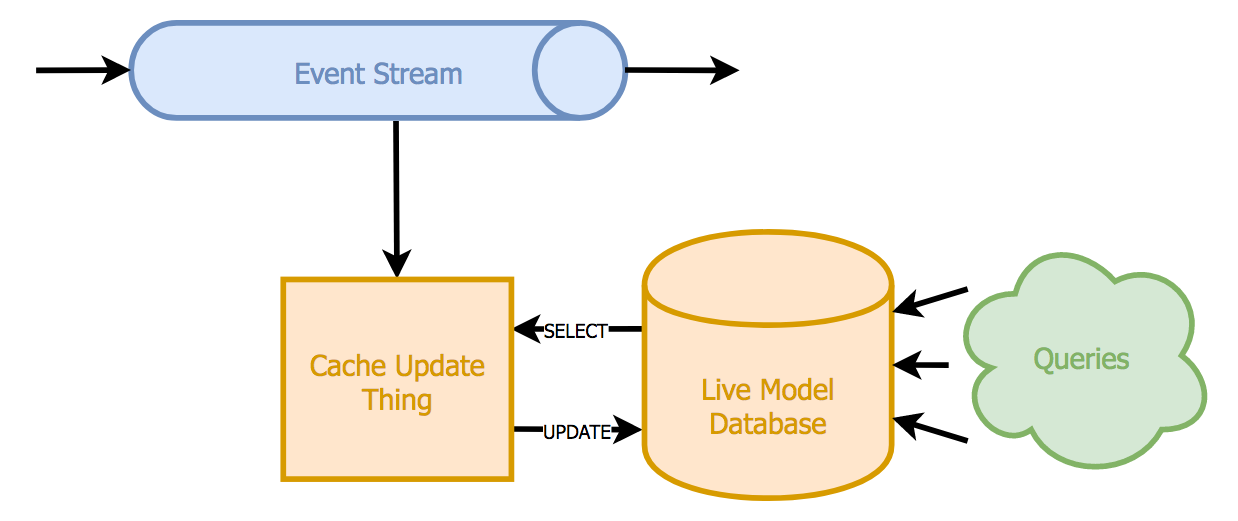
On this plus side, this gives us a database full of up-to-date model data. There are downsides though:
- Because it forms the centre of all live data access, the cache database needs to be *very* fast, which means very large and very expensive.
- Querying the cache database (for example, to see popular products in the last hour) is the only way to access the live model data, which means we need a technology that supports fast lookup *and* efficient querying and aggregations.
- If we choose to periodically offload data to secondary stores, data marts and so on, it just gets us back to the timing issues we had before. Plus the bulk queries to offload data could impact performance.
- For the customer-based example here, this will work fine - if you're lucky enough to have 50 million customers you can afford a big database. However, if you start dealing with real *big data* (like telecoms data), at tens of millions of rows per minute it's going to blow up.
- All your business logic is hidden away, and tied to a database schema which you're going to find hard to change!
Kafka, Confluent and the Table/Stream Duality
It seems that there may be a better way though. Over the past couple of years, the folks working on Kafka, especially those at Confluent, have been looking into this exact problem - how can we turn events to models in real time, without blowing all our cash on servers?
Kafka has, for a long time now, been the worlds greatest data integration tool. It was just a scalable commit log; a queue of things which supported ordering and multiple producers and consumers. It was incredibly reliable and popular, exactly because of its simplicity.
With the addition of Kafka Streams and KSQL, Kafka has grown to become a fully fledged streaming data platform, which provides us with a solution to our events to models problem, out of the box. You can watch Jay Kreps, one of the original authors of Kafka, talking about this here.
In part 2 I’ll walk through how I investigated these cool new features and show a demo based on a Beer Festival…
