Kafka's Beer Festival
November 22, 2018
In part 1 of this series, I explained the age-old problem of converting events (stuff that happens, y’know) into models (details about things; databases). In this post I’m going to get down and dirty, showing some awesome features of Apache Kafka which make this unbelievably simple.

You can find all the code, details of the data and install instructions on my this kaggle.
The Plan
The plan is to spin up a streaming platform, with Kafka at its heart; push in some live ‘sales’ events from the bar of a fictional beer festival, along with some reference data on the beers and breweries…
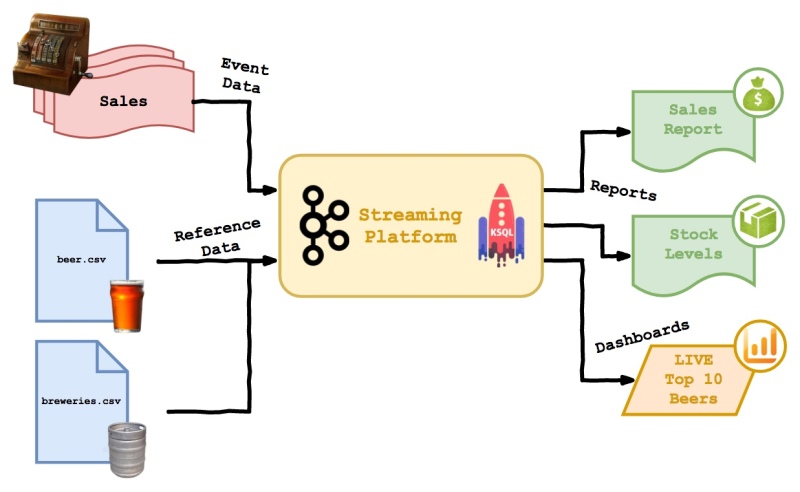
…then to generate some simple reports and live dashboards using only Kafka. This should demonstrate…
- Writing simple producers and consumers using Scala and Avro
- Using basic KSQL to explore data in Kafka
- Keeping reference data up-to-date in real time using tables
- Doing joins and aggregations with KSQL
Prerequisites
If you want to follow along, clone the gihub repo which contains all the code for this article, get the confluent platform up and running on your laptop and build the Scala code with IntelliJ or your dev tool of choice. You’ll also need to download and tweak the source data. All is explained in the README.

Creating Sale Events
In order to monitor beer sales in real time and do reporting, as a beer festival organiser, I want to record every purchase as it happens.
Below are the key methods from the SaleProducer object, which sends a random sale record into the Kafka topic ‘sales’ every second to simulate a busy beer festival.
object SaleProducer {
// ...
def createSale : GenericRecord = {
val sale: GenericRecord = new GenericData.Record(schema)
sale.put("beer_id", beerIds(Random.nextInt(beerIds.size)).toInt)
sale.put("bar", Random.nextInt(4) + 1) // There are 4 bars (i.e. 4 cash registers)
sale.put("price", if(Random.nextDouble() > 0.75) 2 else 1) // Beer festival; 1 token per half
sale
}
def main(args: Array[String]): Unit = {
while (true) {
producer.send(new ProducerRecord[String, GenericRecord](topic, createSale)).get()
Thread.sleep(1000)
}
}
}
Three simple fields are populated: beer_id is a random ID from the beer data, bar is a random choice from 1 to 4 (the cash register used) and price is a random number of tokens: 1 for a half and 2 for a pint. These fields appear in the Avro schema:
{
"namespace": "logicalgenetics.sale",
"type": "record",
"name": "sale",
"fields": [
{"name": "beer_id", "type": "int"},
{"name": "bar", "type": "int"},
{"name": "price", "type": "int"}
]
}
Once the SaleProducer is running, we should see a new Sale event added to the ‘sales’ topic every second. To check this is working we can use the print command in the KSQL client. You can run the KSQL command line client from the confluent directory:
$ bin/ksql
ksql> print 'sales';
Format:AVRO
21/11/18 16:14:58 GMT, null, {"beer_id": 395, "bar": 4, "price": 1}
21/11/18 16:15:00 GMT, null, {"beer_id": 506, "bar": 2, "price": 2}
21/11/18 16:15:01 GMT, null, {"beer_id": 2080, "bar": 4, "price": 1}
21/11/18 16:15:02 GMT, null, {"beer_id": 1128, "bar": 3, "price": 1}
Filtering with Streams
In order to debug, test and investigate my data, as a developer writing sales to a topic, I want to be able to use KSQL to do filtering.
Here we use KSQL to create a stream over the raw ‘sales’ topic, then do some filtering, just to show it’s possible. In the query I’ll select the first 5 sales events from bar number 2…
ksql> create stream sales_stream with (kafka_topic='sales', value_format='avro');
ksql> describe sales_stream;
Name : SALES_STREAM
Field | Type
-------------------------------------
ROWTIME | BIGINT (system)
ROWKEY | VARCHAR(STRING) (system)
BEER_ID | INTEGER
BAR | INTEGER
PRICE | INTEGER
-------------------------------------
ksql> select * from sales_stream where bar = 2 limit 5;
1542817605585 | null | 1934 | 2 | 1
1542817606613 | null | 1128 | 2 | 1
1542817607615 | null | 1105 | 2 | 1
1542817608622 | null | 2264 | 2 | 1
1542817609648 | null | 1530 | 2 | 1
Several really cool things are happening here. Firstly, we created a stream over the top of a raw topic with a single line of KSQL. Secondly, we did a query on it… OK, that sounds pretty lame to those of us who have been doing databases for years… but this is over the top of Kafka, which until recently was just a queue of stuff. All of a sudden, we can query it from a SQL console… trust me, it’s a big deal.
Loading and Joining Reference Data
In order to better understand the beers being sold, as a member of staff at the beer festival, I want to see the beer name for every sale.
OK, let’s unpack that requirement a little: First we’re going to need to load some reference data, which maps beer_id to name. Secondly, we need to have a way to manage changes to this reference data, as updates are part of real life. Finally, we’re going to need to do a join, as the beer records arrive, to add the name to the query results.
Loading the reference data is done by the BeerProducer object. It reads the data from the CSV file, registers a schema and sends each row over in avro format to a topic called ‘beers’. Click through to the source code to see how that works, but it’s much the same as with the SaleProducer above.
ksql> create stream raw_beer_stream with (kafka_topic='beers', value_format='avro');
ksql> CREATE STREAM beer_stream_with_key \
WITH (KAFKA_TOPIC='beer_stream_with_key', VALUE_FORMAT='avro') \
AS SELECT CAST(id AS string) AS id, row, abv, ibu, name, style, brewery_id, ounces \
FROM raw_beer_stream PARTITION BY ID;
ksql> CREATE TABLE beer_table \
WITH (KEY='id', KAFKA_TOPIC='beer_stream_with_key', VALUE_FORMAT='avro');
We did three things in the above snippet. First we created a stream over the beers topic. This stream allows us to query, but has no key column. The second statement creates a new stream, based on the first, converting the numeric ID to a string and setting it as the key. KSQL can only support string keys at the moment. The final step was to create a table, ‘beer_table’. Tables are very cool as they allow a table-like view over a stream, collapsing rows down to their most recent version. Selecting from the table is simple…
ksql> select id, name, abv from beer_table where abv > 0.1;
2565 | Lee Hill Series Vol. 5 - Belgian Style Quadrupel Ale | 0.128
2685 | London Balling | 0.125
2564 | Lee Hill Series Vol. 4 - Manhattan Style Rye Ale | 0.10400000000000001
2621 | Csar | 0.12
Looks like there are four beers in the dataset with a strength above 10% (which is a silly strength for a beer… really!). Now here comes the clever part. In the background I’ll edit the CSV data file and change the ABV of the imaginatively titled “Pub Beer” to 0.11. Then I’ll load the whole dataset again, by posting a whole new set of records to Kafka. Now the topic contains two rows for every beer… but the table just shows the latest, unique records:
ksql> select id, name, abv from beer_table where abv > 0.1;
2564 | Lee Hill Series Vol. 4 - Manhattan Style Rye Ale | 0.10400000000000001
1436 | Pub Beer | 0.11
2565 | Lee Hill Series Vol. 5 - Belgian Style Quadrupel Ale | 0.128
2685 | London Balling | 0.125
2621 | Csar | 0.12
There’s the Pub Beer, in amongst the strongest beers… and just to show the difference, here’s two more queries: one against the table and one against the stream. Remember that the table and the stream are generated entirely from the raw kafka topic ‘beers’ (to which I loaded quite a few duplicates!).
ksql> select id, name, abv from beer_stream_with_key where name = 'Pub Beer';
1436 | Pub Beer | 0.05
1436 | Pub Beer | 0.05
1436 | Pub Beer | 0.05
1436 | Pub Beer | 0.05
1436 | Pub Beer | 0.05
1436 | Pub Beer | 0.11
1436 | Pub Beer | 0.05
1436 | Pub Beer | 0.11
ksql> select id, name, abv from beer_table where name = 'Pub Beer';
1436 | Pub Beer | 0.11
So now we have a way to load and manage reference data - keeping track of the latest values as they change and tracking/managing versions with minimal effort. Last step is to join the event data (sales) to the reference data (beers) and show some readable info as sales appear…
ksql> select bar, price, name, abv \
from live_sales LS \
join beer_table BT on (LS.beer_id = BT.id) \
limit 10;
1 | 1 | Hoodoo Voodoo IPA | 0.062
2 | 1 | Pumpkin Porter | 0.051
4 | 1 | Humpback Blonde Ale | 0.042
3 | 2 | Hoppy Bitch IPA | 0.063
4 | 1 | Manhattan Gold Lager (1990) | null
3 | 1 | Single Engine Red | 0.057999999999999996
4 | 1 | Heliocentric Hefeweizen | 0.047
1 | 2 | Hopluia (2004) | null
3 | 1 | Hydraulion Red | 0.053
3 | 1 | Cane and Ebel | 0.07
Status Update
So, I think the following diagram shows where we are so far. We’ve loaded live events and reference data, demonstrated how updates to reference data can be managed and shown how these two datasets can be joined within Kafka in real time… personally, I am both astonished and in love…
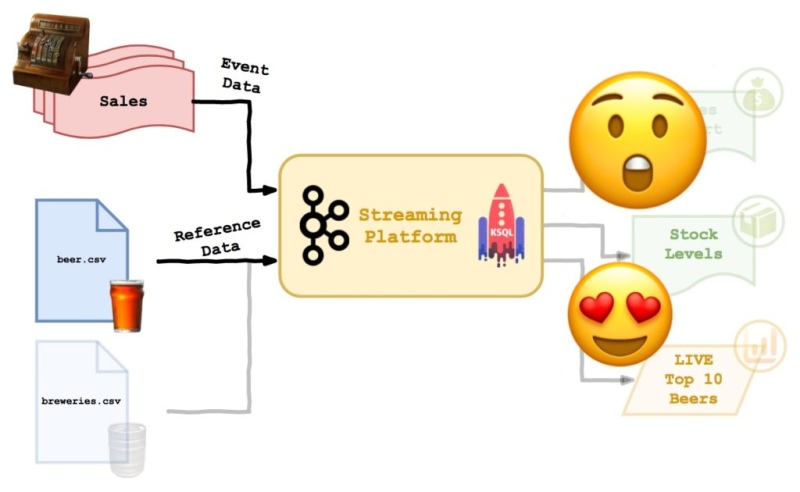
For me, the table semantics are the killer feature here. This blog series is about converting events to models, and these snazzy new tables do much of the heavy lifting in that area. Updates to a cache are no longer needed, as the streaming platform handles updates internally.
The ability to join and filter in SQL means that defining the ‘rules’ for creating and updating models is easier too. There is less software to write and fewer external applications to build and maintain.
In the next instalment I’ll look at aggregations and reporting in batch and real time. Stay tuned!